
PDFファイルの編集って何を使っていますか?
無料のものも色々あるけど、結構機能が限定されているんですよねぇ……
そこでなんやかんや、色々編集できる「PDFelement」というソフトのレビューを、Wondershare様から依頼されたので使ってみました!
ということで、ご紹介とレビューです!
PDFelementってどんなことができるの?
高機能なPDF編集ソフトです。
内容はこんな感じ。
| 内容 | 標準版 | プロ版 |
|---|---|---|
| 価格:年間プラン(年ごとに契約更新を行うプラン) | 4,980円 | 8,280円 |
| 価格:ライフタイムプラン(買い切り) | 5,980円 | 9,980円 |
| PDF作成 | ○ | ○ |
| PDFを Word, Excel, Powerpointに変換 | ○ | ○ |
| PDF内のオブジェクトを直接編集 | ○ | ○ |
| PDF文書を閲覧 | ○ | ○ |
| PDFに注釈を追加 | ○ | ○ |
| フォームに入力 | ○ | ○ |
| 暗号化 | ○ | ○ |
| PDF圧縮 | ○ | |
| OCR光学文字認識 | ○ | |
| フォームフィールド作成 | ○ | |
| スキャナーからPDFを作成 | ○ | |
| OCRのバッチ処理 | ○ | |
| 暗号化のバッチ処理 | ○ | |
| PDF圧縮のバッチ処理 | ○ |
ちなみに学生や教員の方は、割引があるのでお得です!
| プラン | 標準版 | プロ版 |
|---|---|---|
| 年間プラン | 3,380円 | 5,580円 |
| ライフタイムプラン | 4,380円 | 7,280円 |
PDFelement必要スペック
PDFelementをインストールするには、このようなスペックが必要です。
| 項目 | 要件 |
|---|---|
| OS | XP/Vista/7/8/8.1/10 |
| CPU | 1 GHz以上 |
| RAM | 512 MB以上 |
| HDD空き | 500 MB以上 |
| 必要コンポーネント | Microsoft .NET Framework 4 |
いまどき使用されているPCなら、らくらくクリアな内容ですね。
インストール
インストーラをダウンロードしたら、実行します。

インストールはよくあるポチポチで完了します。

インストール先を変更したいときは、右下の「インストール先を変更」から行うことができます。
デフォルトインストール先が「C:\Program Files (x86)」なので、基本的には特に変更は不要だとは思いますが……
OKだったら「インストールボタン」で進めていきましょう!
注意点
インストールが完了すると、PDFファイルを開くデフォルトアプリが、「PDFelement」に変更されます。
「デフォルトで開くときは、このアプリでPDF読みたいんだけど!!」
って人は、デフォルトアプリを変更しましょう。
エクスプローラから、PDFファイルを選んでプロパティから設定できます。
Pro版の登録
右上の「ログインボタン」を選択。
下部にある「アカウント作成」を選択して、登録用のアカウントを作成します。 パスワードは、「英数字6~16桁」という制限があります。
完了すると、こんな画面が出てきます。

ここで購入を押すと、PDFelementの購入画面に進むことができます。
シリアルナンバーを持っている場合、登録を行います。
「アカウントのを確認する」のリンクを選択し、出てきたページからログインします。
こんな感じの画面が表示されるので、サイドメニューから「製品の引き換え」を選択。
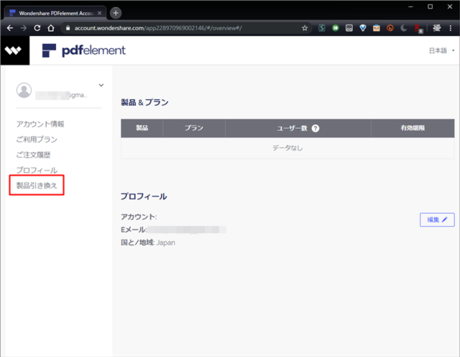
「シリアル番号」を選択し、シリアル番号を入力→「引き換えるボタン」を押します。

「成功」というポップアップが出てくればOKです!

PDFelementに戻って、右上の「アカウントボタン」を押します。
アカウント情報の画面から「最新の状態に更新」を選択。
ユーザー権利がProfessionalになってます!
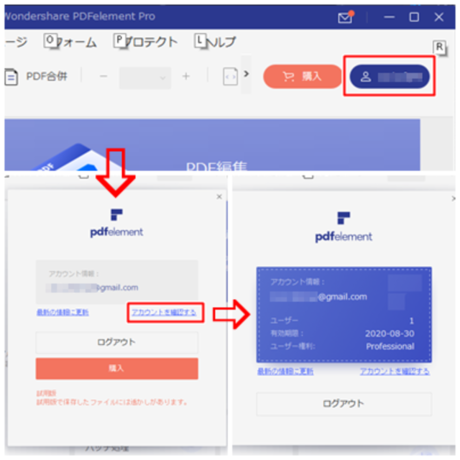
これで有効期限までは、Pro版として使用できます!
PDFを変換してみる
今回はGoogle Booksからダウンロードした、PDFの電子書籍「夏目漱石 - こころ」を使用します。
手順は相当簡単。
たった3ステップです。
- メイン画面からPDFの変換を選択
- 変換したいPDFを選択
- 変換結果の設定
- 保存名
- フォーマット(種類)
- 設定
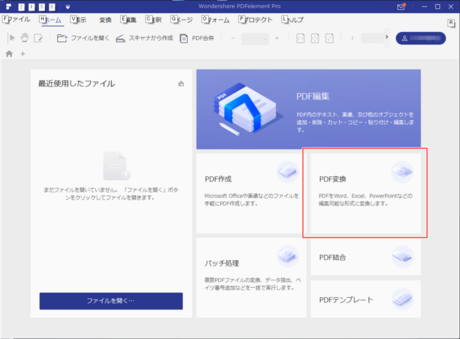
変換できるフォーマットは、これだけあります。
- PDF/A(*.pdf)
- Word(*.docx/doc)
- Exce(*.xlsx/xls)
- PowerPoint(*.pptx/ppt)
- 画像(*.jpg/png/gif/tiff/bmp)
- RTF(*.rtf)
- テキスト(*.txt)
- HTML(*.html)
- 電子書籍(*.epub)
今回はWordへの変換で試したのですが、ここの設定次第で、OCR*1されるかどうかが変わりました。
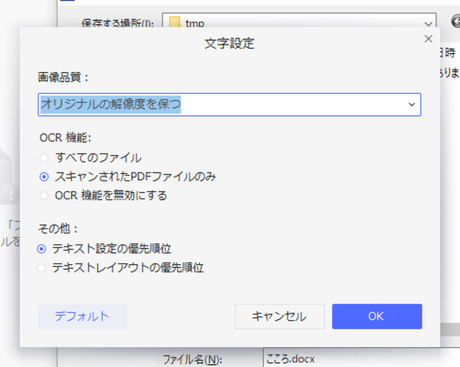
元にしていたファイルは、文章がテキストデータとして埋め込まれていました。
しかし「スキャンされたPDFファイルのみ」にした場合、1ページが画像として貼り付けられたような形でWordファイルが生成されました。
「すべてのファイル」にした場合、OCR機能が働きました。
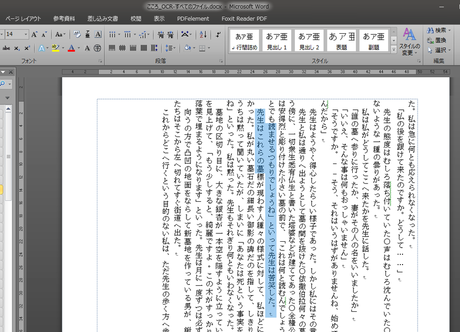
ただし、パッと見ただけでも
- 文章のブロックが、テキストボックスで貼り付けられた形となっている(通常Wordで文章を書くときのように入力されているわけではない)
- 「。」が「〇」となっている箇所がある
という点が気になりました。
とはいえ、その他のテキストは、基本的にはOCRのパワーでテキスト化されているように見えました。
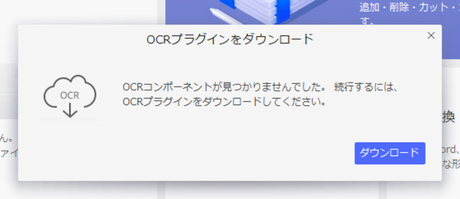
ちなみに初めてOCRを使おうとしたとき、プラグインのダウンロード画面が出ました。
これが出たらダウンロードしましょう。
PDFをOCRしてみる
適当なPDFを作って、OCRしてみました。
作ったのがこれ。

上のブロックが画像で、下のブロックがテキストデータです。
このファイルをPDFelementで開いて、「変換」→「OCR」を選択します。

すると
- 検索可能な画像
- 画像ファイルのままで、画像にテキスト情報を埋め込む
- 検索時にこのテキスト情報がヒットするので、検索可能になる
- 編集可能なテキスト
- PDFの文字の画像をテキスト情報に置き換える
の2パターンから選択することができます。
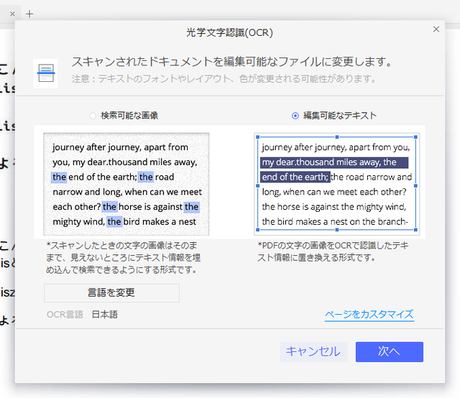
今回は、「編集可能なテキスト」にしました。次へ。
処理が実行が行われて、完了まで待つと……
画像データだった所も、テキストに変換されました!
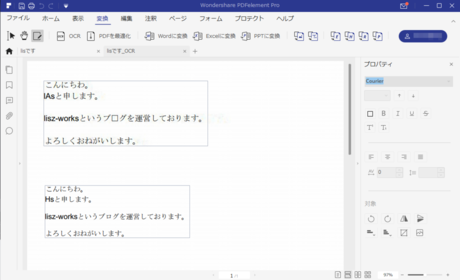
ほぼ成功していますね!
とはいえ
- 「lis」が「lAs」や「Hs」になっている
- 画像側のブログの「ロ」が「□」になっている
という変換ミスがありますね。
フォントの問題もあるかもしれませんが、OCRは100%の互換率で、画像→テキストにはできないので、適宜確認と修正をするのがベストです!
とはいえ対象のデータが、ほぼテキスト化、なんてことができるわけですから、全て手入力で写すより遥かに効率的です。
あとがき
PDF編集ソフト Wondershare PDFelementについてでした!
簡単操作でPDF編集ができるので、気になった方は是非お試し下さい!
*1:手書きや印刷物の文字を、PCのテキストに変換する文字認識機能のこと。